 1-888-661-8967
1-888-661-8967

Clustering Techniques for Data Segmentation: A Glimpse
Artificial Intelligence (AI) systems can process and analyze massive data sets which makes them uniquely suitable for data segmentation processes. The process through which an AI algorithm learns is known as machine learning (ML).
An AI algorithm needs to learn from training data (sample set) first. There are three modes in which an AI algorithm learns from data:
- Unsupervised machine learning
- Supervised machine learning
- Semi-supervised machine learning
While we need well-labelled and organized data for supervised and semi-supervised learning, unsupervised machine learning can be performed on raw data or technically speaking unlabeled data.
In unsupervised machine learning, an ML-based algorithm is written and is run on the sample data set. The algorithm recognizes the data point on it’s own and depending on the relationship between them, it assigns weights to these data points.
We may use various kinds of collating algorithms to segment this data. Clustering is among the most commonly used methods to perform unsupervised machine learning.
Clustering
For clustering, we group data points based on their weights. The following three are the major types of clustering algorithms:
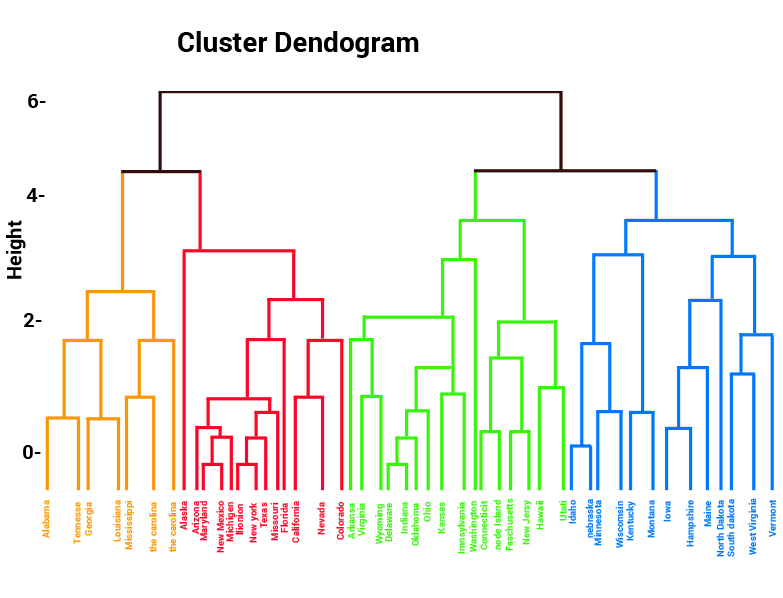
1. Hierarchical Clustering
Each merging level represents a level in the grouping hierarchy of the algorithm. The process continues until there is just one group left.
Hierarchical Clustering is best suited for discovering hidden trends in a data set. However, since it considers that each data point is relevant, this method can incur performance overhead on the system.
2. Density Based Clustering
While data groups are formed the same way as they are formed in hierarchical clustering, this method assumes that only tightly populated groups are important data points and the rest is just noise.
Everything outside the data points considered as core points or border points, is considered noise. Consider this image, for example:
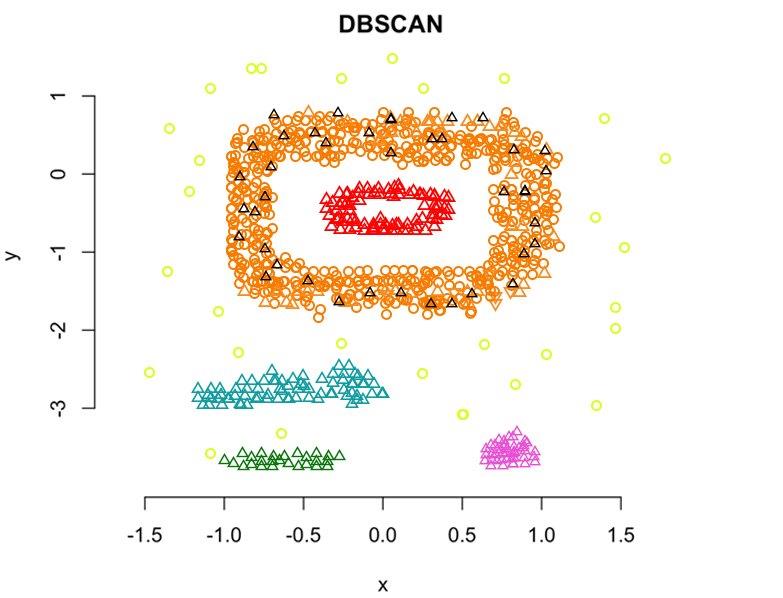
This method is highly useful in real-life applications as it rejects non-relevant data early in the process. It is applied in cases where you are fairly confident that all clusters will have a similar density. However, it fails at finding consensus across the whole dataset.
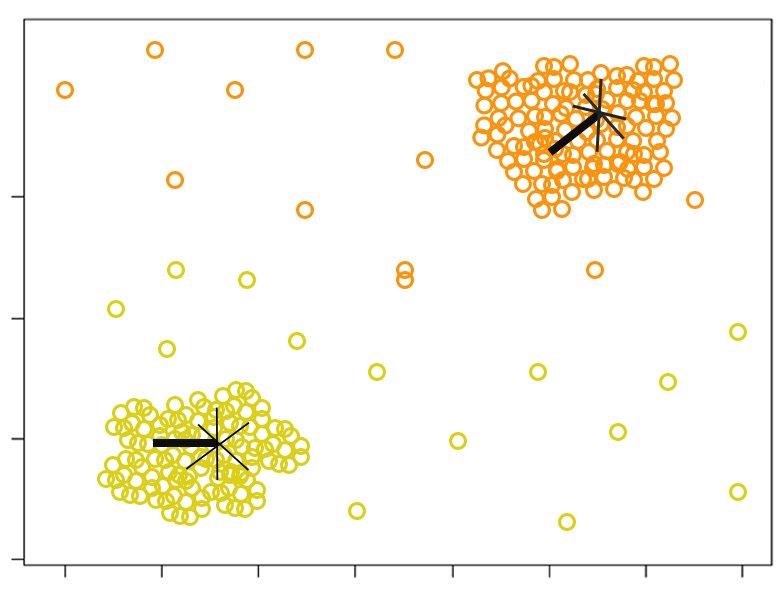
3. K-Means Clustering
K-means clustering begins with k randomly chosen data points, called means. Taking these means as centeroids, the algorithm then clusters data points around it. After the first iteration is done, the mean of all clusters is recalculated and the data points in clusters are mapped again to conform with the new mean.
This process goes on until the cluster values stop changing.
This algorithm ensures consensus across the whole data set.
What we discussed here only scratches the surface of some of the most popular clustering techniques. Depending on the solution required, you might need to employ a certain variation or a mix of variations of these algorithms.
If you are considering implementing an AI solution for your organization, it is much more convenient and cost-effective to get help from industry experts like AISmartz. AISmartz offers AI consulting services, ensuring a hassle-free end-to-end solution implementation.